技术/产品/市场三维度解释闪存厂商闪迪涨幅远高于DRAM三巨头的核心逻辑
自 2025 年 2 月从西部数据独立拆分以来,闪迪在 AI 企业级 SSD 爆发和“去周期化”长约的利好下,年内股价暴涨超 400%,一年多来累计涨幅甚至飙升了 12 倍至 40 倍不等(受拆分低基数催化)。 相比之下,DRAM
来源声明:本文由 @LMDFinance 首发于 X,本站转载仅供学习交流,不构成投资建议。

自 2025 年 2 月从西部数据独立拆分以来,闪迪在 AI 企业级 SSD 爆发和“去周期化”长约的利好下,年内股价暴涨超 400%,一年多来累计涨幅甚至飙升了 12 倍至 40 倍不等(受拆分低基数催化)。
相比之下,DRAM 巨头虽然也享受 AI 红利,但美光(Micron)近一年涨幅约为 1.7 倍至 7 倍,SK 海力士和三星因高基数及产能内卷,涨幅远逊于闪迪的爆发力,闪迪(SanDisk)的涨幅彻底碾压了 DRAM 三巨头。
以下,我们来从技术/产品/市场三个维度拆解具体原因。
一.DRAM和闪存的全面对比
DRAM(动态随机存取内存)和闪存(Flash Memory)是现代电子设备中最核心的两类存储技术,它们在工作原理、性能和用途上有着本质的区别。
🛠️ 核心技术差异
数据易失性:DRAM 属于易失性存储。断电后数据立即消失。闪存属于非易失性存储。断电后数据依然长期保存。
基本存储单元:DRAM 使用电容和晶体管组合。利用电容是否有电荷代表0和1。闪存使用浮栅晶体管。利用捕获的电子长期锁定状态。
刷新需求:DRAM 必须不断刷新充电。电容漏电极快,每秒需刷新数百次。闪存无需刷新。电子被物理隔离,可保存数年。
⚡ 性能与寿命对比
读写速度:DRAM 极快。延迟在纳秒(ns)级别。闪存较慢。延迟在微秒(μs)或毫秒(ms)级别。
读写寿命:DRAM 近乎无限次。几乎没有物理磨损。闪存寿命有限。擦写次数有上限(约1,000到100,000次),容易老化。
擦除粒度:DRAM 支持字节级随机读写。闪存必须以块(Block)为单位擦除,以页(Page)为单位写入。
💰 成本与存储密度
制造成本:DRAM 成本极高。单位容量的价格远贵于闪存。闪存成本极低。可以通过3D堆叠技术大幅降低每GB成本。
存储容量:DRAM 容量较小。单条内存通常为8GB到64GB。闪存容量极大。单个固态硬盘或U盘可达数百GB甚至数TB。
📱 应用场景分类
DRAM 的角色:充当运行内存(RAM)。用于连接CPU,临时存放正在运行的系统和软件数据。
闪存 的角色:充当长期存储介质(ROM/Storage)。用于固态硬盘(SSD)、U盘、SD卡以及手机内置存储(闪存芯片),存放照片、文件和安装包。
二.做闪存的闪迪为什么涨得比DDRM三巨头更厉害?
这次 AI 驱动的高带宽内存(HBM)大涨,主要做闪存(NAND Flash)的闪迪(SanDisk)股价反而涨得更厉害(年内涨幅超 400%-500%),表面上看违背了“AI 只需要高速内存”的常识,但背后其实隐藏着华尔街对 AI 基础设施底层架构变化的重估逻辑。
闪迪暴涨并跑赢美光等 HBM 巨头,核心原因在于以下四个关键催化剂的共振:
1. 独立拆分“消除折价”,成为最纯粹的 AI NAND 标的
闪迪于 2025 年 2 月正式从西部数据(Western Digital)独立拆分上市。
此前:闪迪的闪存业务与毛利较低、增长缓慢的 HDD(机械硬盘)业务捆绑在一起,估值遭到严重压制(综合企业折价)。
拆分后:闪迪变成了一家没有任何债务负担、业务极度纯粹的闪存巨头。华尔街大笔资金为了追逐 AI 存储红利,将其作为最纯粹的标的疯狂买入,推动了极具爆发力的“补涨”与重估。
2. AI 架构巨变:NAND 闪存被作为“慢速内存”使用
AI 的演进让闪存跨界抢了内存的饭碗。
DeepSeek 等模型的架构创新:验证了在模型推理和训练中,利用先进的算法可以将超大容量的企业级 SSD(NAND 闪存)当作“慢速内存”来协同计算。
英伟达新架构的推动:AI 巨头在硬件层面为 NAND 创造了全新的应用场景,闪存不再只是单纯的“数据仓库”,而是直接参与到 AI 的吞吐效率和推理工作负载中。
3. 数据中心狂飙:锁定 420 亿美元长期合同“去周期化”
闪迪成功斩获了亚马逊、微软、谷歌和 Meta 等四大云巨头(Hyperscalers)的高达 420 亿美元的长期供应合同。
传统存储股极易受到行业周期影响(大涨大跌)。但闪迪通过这些长期合同,确保了未来数年企业级 SSD 的暴利订单,成功实现了“去周期化”。
其最新财报显示,数据中心业务同比激增 645%,非 GAAP 毛利率达到了半导体行业罕见的 78.4%,极强的定价权彻底点燃了资本市场。
4. HBM 产能挤占引发 NAND 闪存全线暴涨
三大内存巨头(三星、SK海力士、美光)为了全力满足英伟达的 HBM(DRAM)需求,将大量的晶圆产能和研发精力从普通闪存转走。
这导致全球 NAND 闪存的供给极度收缩,而 AI 服务器对大容量 NVMe SSD 的需求又呈指数级爆发,造成了极为严重的供需错配。
闪迪顺势多次上调产品价格(单次宣布涨价达 10% 以上),呈现出比 HBM 更陡峭的利润爬升曲线。
三.数据中心为何狂买DDRM的同时也拼命买SSD?
数据中心拼命采购 DDR5/HBM(DRAM 内存) 的同时疯狂囤积 企业级 SSD(闪存),是因为 AI 模型的大小超出了内存的物理极限,数据中心必须用这两种介质构建一套“速度(DRAM)+ 容量(SSD)”的冷热数据分层协同架构。
单独依靠任何一种存储,AI 算力(如英伟达 GPU)都会因为“断供”数据而瘫痪。
1. 核心矛盾:AI 模型的“胃口”远超内存容量
当前最先进的 AI 大模型和训练数据集规模呈现指数级暴涨。
训练数据集(几 TB 到几十 TB):这些海量的数据不可能全部塞进价格昂贵、容量有限的 DRAM 内存中。
模型参数(数万亿参数):即便是像英伟达最顶级的 HBM 内存集群,往往也只能放下模型的一部分。
解决办法:数据中心必须用 SSD 充当“主力仓库” 存放整个庞大的数据集与模型检查点(Checkpoints),然后通过高速网络不断将数据 “泵入”DRAM 内存 进行实时计算。
2. DRAM 与 SSD 在 AI 流程中的核心分工
数据中心狂买这两者,是因为它们在 AI 的训练(Training)和推理(Inference)中各自卡死了关键节点:
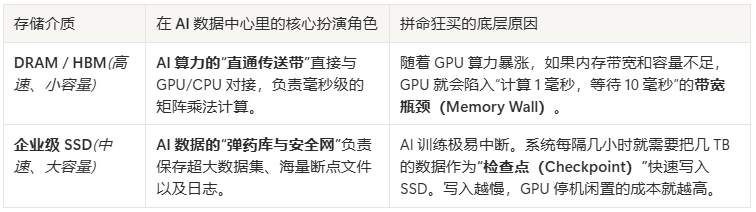
3. 技术突破:SSD 正在跨界扮演“慢速内存”
正如前文提到,AI 架构的软件创新打破了内存与闪存的物理界限。
近内存计算优化:通过优化算法(例如类似 DeepSeek 的混合专家架构 MoE),系统可以做到“用哪部分参数,就临时从 SSD 读取哪部分”。
PCIe 5.0 吞吐暴涨:最新企业级 SSD 采用了 PCIe 5.0 技术,读取速度高达 14GB/s 以上。配合 NVIDIA GPUDirect Storage (GDS) 技术,数据可以绕过 CPU,直接从 SSD 冲进 GPU 显存。这让 SSD 成功客串了“慢速内存”的角色,极大地缓解了 DRAM 的容量压力。
4. 产能连锁反应:买不到 HBM,只能用超级 SSD 顶替
由于全球 HBM 和高性能 DDR5 DRAM 的产能被严重挤爆,很多数据中心面临“有钱也买不到足够内存”的窘境。
为了不让昂贵的 AI 服务器和 GPU 闲置,数据中心被迫转向“用更大量的超高速 NVMe SSD 来做虚拟内存补偿”的方案。
这种“以闪存代内存”的妥协方案,直接拉动了 30TB、64TB 甚至 128TB 这种超大容量企业级 SSD 的采购订单呈现出数十倍的爆发。
附1:PCIe 5.0 NVMe SSD 与 DDR5 内存 之间的具体速度差异有多大
DDR5 内存的传输速度比 PCIe 5.0 SSD 快 3 到 6 倍,而延迟(响应时间)则快了近 1000 倍。
具体数据对比如下:
吞吐速度:顶尖的 PCIe 5.0 NVMe SSD 的最高读取速度约为 14 GB/s。而标准的单通道 DDR5-6400 内存带宽可达 51.2 GB/s,在服务器多通道配置下更可飙升至数几百 GB/s。
物理延迟:DDR5 内存的延迟极低,仅为 10 到 15 纳秒(ns)。而 PCIe 5.0 SSD 即使通过 NVMe 协议优化,延迟仍在 10 到 50 微秒(μs) 级别。
因此,SSD 负责大容量的数据吞吐,而核心的实时计算必须依赖内存。
附2:GPUDirect Storage (GDS) 技术 是如何让 SSD 绕过 CPU 直接给 GPU 喂数据的?
GPUDirect Storage (GDS) 技术通过在 NVMe SSD 和 GPU 显存(HBM/VRAM)之间建立一条直接的 PCIe 硬件通道,彻底绕过了 CPU 和系统内存(DRAM)。
传统模式:数据必须先从 SSD 读入系统内存,由 CPU 解压处理后,再复制到 GPU 显存。这导致 CPU 负荷过高,系统内存带宽被严重挤占,成为速度瓶颈。
GDS 模式:通过定制的内部驱动,GPU 的直接内存访问(DMA)引擎可以直接向 SSD 发起读取请求。数据通过 PCIe 交换机(Switch)直接从闪存颗粒冲进 GPU 显存。
这消除了多次数据复制的延迟,使吞吐量提升了 2 到 10 倍,同时将 CPU 的负载降低了近 99%。
评论
请 登录 或 注册 后参与评论。