美国哪些科技大公司在研发AI芯片,性能等对比
美国主要科技大公司(Big Tech及半导体巨头)在AI芯片(主要是AI加速器/ASIC/GPU)领域的研发情况如下(截至2026年5月数据)。
来源声明:本文由 @LMDFinance 首发于 X,本站转载仅供学习交流,不构成投资建议。

美国主要科技大公司(Big Tech及半导体巨头)在AI芯片(主要是AI加速器/ASIC/GPU)领域的研发情况如下(截至2026年5月数据)。 NVIDIA仍主导市场(约80%份额),但超大规模数据中心(如Google、Amazon、Microsoft、Meta)大力开发自定义ASIC以降低对NVIDIA依赖、优化成本和能效,尤其在inference(推理)领域。
一.综合比较列表(重点公司)
使用表格形式比较关键维度:核心产品/架构、主要优势、最新进展(2025-2026)、市场/应用定位、相对NVIDIA地位。
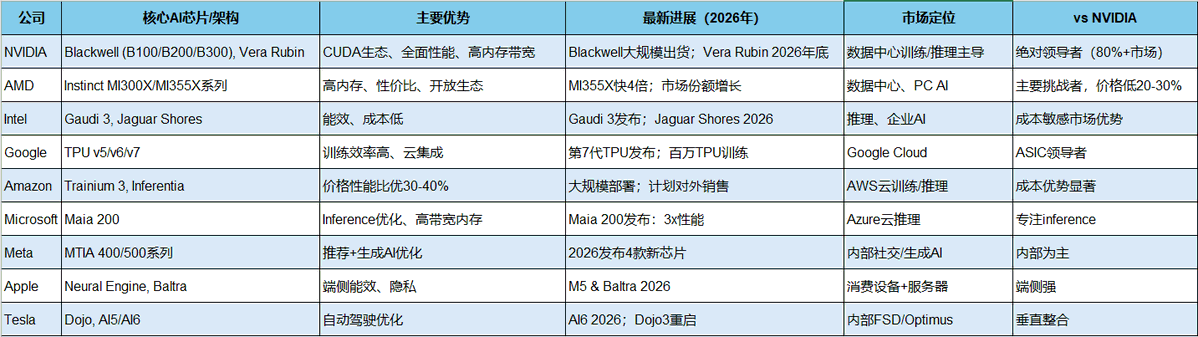
其他 notable:Broadcom是定制芯片主力;Cerebras(大芯片WSE)、SambaNova等初创也活跃,但非“大公司”核心。
二.市场格局
1. NVIDIA
英伟达仍是王者(Blackwell/Vera Rubin驱动增长),但自定义ASIC浪潮强劲。

NVIDIA GPU芯片是目前全球计算领域的核心硬件,广泛应用于人工智能、游戏显卡、数据中心和智能驾驶等多个数字产业。
1). 核心架构演进
NVIDIA 的 GPU 芯片性能提升极大地依赖于其底层微架构的迭代:
Blackwell 架构 (2024-2026):专注于极致的万亿参数级大语言模型(LLM)训练与推理。
Hopper 架构 (2022):以 H100、H800 为代表,奠定了现代生成式 AI 算力的基础。
Ada Lovelace 架构 (2022):面向消费级显卡(RTX 40系列),主打光线追踪与 DLSS 3 帧生成技术。
Ampere 架构 (2020):涵盖企业级 A100 和消费级 RTX 30系列,属于全能型算力基石。
2). 主要产品线分类
➊ 数据中心与 AI 芯片(企业级)
NVIDIA Blackwell B200 / B100:专为万亿参数级大模型设计,单颗芯片集成超千亿晶体管。
NVIDIA Hopper H100 / H200:目前全球 AI 训练的黄金标准,采用 HBM3e 高带宽显存。
NVIDIA Ampere A100:经典的高性能计算与深度学习芯片,支持灵活的 MIG(多实例 GPU)切分。
NVIDIA L40S / L4:面向企业级 AI 推理、图形渲染和全向宇宙(Omniverse)的高性价比方案。
➋ 消费级显卡芯片(GeForce 系列)
GeForce RTX 4090 / 4080 / 4070 等:基于 Ada Lovelace 架构,集成 Tensor Core 与 RT Core,支持本地运行轻量级大模型。
GeForce RTX 30 系列:基于 Ampere 架构,目前市场上性价比高、普及率广泛的上一代主流游戏及开发芯片。
➌ 智能驾驶芯片(DRIVE 系列)
NVIDIA DRIVE Thor:新一代集中式汽车计算平台,单颗芯片算力最高可达 2000 TFLOPS,集成自动驾驶和智能座舱。
NVIDIA DRIVE Orin:当前量产智能汽车的主流旗舰芯片,提供最高 254 TOPS 的算力。
2. Google TPU

Google 的 AI 芯片是以 TPU(Tensor Processing Unit,张量处理单元)为主轴的自研专用加速器(ASIC)体系,是全球唯一在生态和算力规模上能与 NVIDIA GPU 正面抗衡的芯片矩阵。
与 NVIDIA 出售独立芯片的商业模式不同,Google 的 TPU 主要通过 Google Cloud(谷歌云)以云端算力集群(AI Hypercomputer)的形式对外提供服务,全面支撑了从 Google 自身的 Gemini 大模型 到 Anthropic(Claude)等头部 AI 企业的超大规模算力需求。
1). 最新芯片架构与路线图
Google 已经打破了传统“单款芯片兼顾训练与推理”的常规,全面走向专用化分工。
第八代 TPU:进入“智能体时代”(2026年最新发布)
在 2026 年 Google Cloud Next 大会上,Google 首次将 AI 芯片分拆为两款独立硬件:
TPU 8t (Training):专为超大规模模型训练设计。单个集群(Superpod)可互联 9,600 颗芯片,提供高达 121 Exaflops 的算力,同等价格下训练性能较前代提升 2.8 倍。
TPU 8i (Inference):专为超低延迟 AI 推理与智能体(AI Agents)设计。针对多步骤规划、高并发解码和实时交互进行了深度硬件优化,推理速度提升 80%。
前代核心主力
第七代 Ironwood TPU (2025):全能型大模型芯片,采用 100% 液冷架构,单芯片峰值算力高达 4614 TFLOPs (FP8),核心性能指标及每瓦能效比直接对标 NVIDIA Blackwell (B200) 芯片。
第六代 Trillium TPU (2024):主打极高性价比的过渡期算力中坚,其 HBM 内存带宽和计算密度较 V5 代实现倍增。
TPU v5p / v5e (2023):目前仍在谷歌云大量服役的基础算力,是早期训练 Gemini 1.0/1.5 模型的核心功臣。
2). Google AI 芯片的三大底层杀手锏
OCS (Optical Circuit Switching) 光电路交换技术:Google 数据中心不依赖传统网络交换机,而是通过光学镜片转动动态路由光信号。即使集群中某颗 TPU 突发故障,网络能动态绕行,确保数万颗芯片的训练任务零间断运行。
Google Axion (自研 Arm CPU):为了彻底摆脱 x86 架构的限制,最新的 TPU 8t/8i 集群全面托管在 Google 自研的 Axion 处理器上,由其负责海量数据的预处理和调度,实现了纯自研生态的垂直整合。
硬件级 SparseCore(稀疏核心):专为混合专家模型(MoE,如 Gemini 架构)优化的嵌入式处理器,能够极速处理稀疏门控网络中的动态路由,这也是 Google 运行多模态大模型成本远低于同行的秘密武器。
3). Google TPU 与 NVIDIA GPU 的直观对比
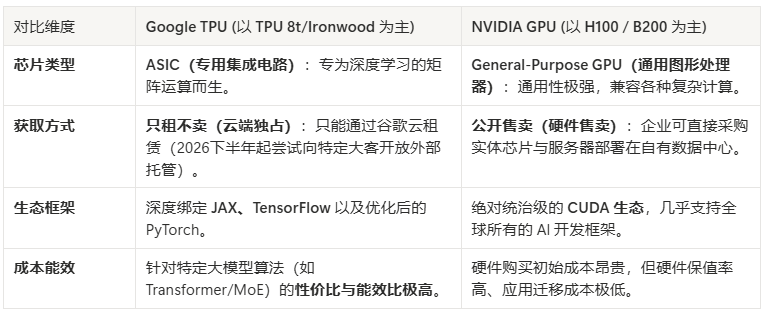
3. Amazon AWS

Amazon(亚马逊 AWS)的 AI 芯片是专为降低云端大模型计算成本而设计的自研定制芯片体系(ASIC)。其商业逻辑非常纯粹:打破 NVIDIA 在算力上的垄断,以“一半的价格”提供具备高度竞争力的替代方案。
在商业模式上,亚马逊迎来了重大转变:以往这些芯片只通过 AWS 云平台以“只租不卖”的形式提供服务,但自 2026 年起,亚马逊正正式考虑对外直接销售整机架的芯片实体与硬件,直接与 NVIDIA 的硬销售模式展开正面竞争。目前,亚马逊的芯片业务年化营收已突破 200 亿美元。
1). 核心产品线:双子星战略
Amazon 的 AI 芯片同样遵循“训练”与“推理”的分工职责,主要包含两大核心品牌:
训练芯片:AWS Trainium 系列(主打极致极致性价比)
Trainium3 (Trn3) —— 最新 3nm 旗舰 (2026年全面部署):亚马逊首款采用台积电 3nm(N3P)工艺的 AI 芯片。单芯片可提供 2.52 PFLOPs 的 FP8 算力,配备 144GB HBM3e 显存,每瓦能效比前代提升 4 倍。目前已被 Amazon Bedrock 平台大量用于多模态和推理(Reasoning)大模型的底层加速。
Trainium2 (Trn2):2025年大规模服役的算力中坚。由近 50 万颗 Trainium2 组成的 Project Rainier 集群,正全力支撑顶尖 AI 独角兽 Anthropic 训练其新一代 Claude 大模型,其性价比相较 NVIDIA H100 提升了 30% 到 40%。
推理芯片:AWS Inferentia 系列(主打单次调用低成本)
Inferentia2 (Inf2):当前亚马逊云端推理的旗舰芯片,专门优化了 Llama 3、Stable Diffusion 等生成式 AI 的部署。单个芯片提供 190 TFLOPS (FP16) 算力,通过自研的 NeuronLink 实现多芯片高速互联,单次 AI 推理的运行成本相比传统 GPU 最高可降低 50% 以上。
Inferentia1 (Inf1):亚马逊在 2018 年推出的初代芯片,成功支撑了亚马逊 Alexa 语音助手的海量日常实时预测需求。
2). 亚马逊 AI 芯片的底层技术王牌
NeuronLink 与集群扩展能力:在最新的 Trn3 UltraServer 服务器中,亚马逊通过高速 NeuronLink 互联网络将多达 144 颗 Trainium3 芯片打包成单个算力超级节点,且整体数据中心集群(UltraClusters 3.0)最高可将 100 万颗 Trainium 芯片连接成单一算力怪兽。
Neuron SDK 生态框架:这是开发者将大模型迁移至亚马逊芯片的桥梁。它原生支持 PyTorch、JAX 和 TensorFlow,允许企业无需修改复杂的底层 CUDA 代码,就能把在 NVIDIA GPU 上跑的模型直接编译运行在 Trainium 芯片上。
原生支持先进数据格式:Trainium3 在硬件层原生增加了对 MXFP8 和 MXFP4 开放数据格式的支持,在不牺牲模型精度的前提下,让算力密度和显存空间翻倍,非常契合最新一代 Agentic(智能体)和复杂推理模型的结构。
3). Amazon 与 NVIDIA、Google 的芯片格局对比

总的来说,超大规模数据中心(hyperscalers) 通过自研芯片已实现数十亿收入,并计划对外销售,侵蚀NVIDIA份额(尤其inference,因训练更依赖GPU)。
在AI芯片领域,AMD与英特尔(Intel)正通过不同策略全力追赶。
4. Microsoft AI 芯片
与AMD、英特尔等传统芯片厂商销售硬件的逻辑不同,微软(Microsoft)在AI芯片领域采取的是“软硬一体、全栈自研、专供云端(Azure)”的系统级战略。微软不单独对外售卖芯片,而是将其作为基础设施部署在 华盛顿、爱荷华、凤凰城等地的 Azure 数据中心 内,用于驱动 OpenAI 的最新大模型(如 GPT-5系列)、微软自己的 Copilot 以及云端客户的 AI 服务。
微软的自研芯片家族主要采用“AI加速器(Maia系列)+ 定制CPU(Cobalt系列)”的双翼组合:
1)、 核心AI加速芯片:Azure Maia 系列(ASIC)

Maia 是微软专门针对大规模语言模型(LLM)的微调、训练与高并发推理量身定制的专用加速卡:
Azure Maia 100(第一代破局者):于 2023 年底发布,采用台积电 5nm 工艺,集成了高达 1050 亿个晶体管。 由微软与 OpenAI 团队深度联合开发与调优,主要用于承载早期 ChatGPT、Bing AI 及 GitHub Copilot 的底座算力。
Azure Maia 200(第二代智算旗舰):升级采用台积电 3nm 先进制程,配备 216GB HBM3e 高带宽内存,提供高达 7TB/s 的内存带宽。 极致的推理经济学:官方定位其为“最高效的推理系统”,在某些特定指标上性能超过了谷歌和亚马逊的同类芯片,每美元性能相比前代提升了 30%。 核心任务:优先部署于微软“超级智能团队”(Superintelligence team),专为强化学习(RL)、合成数据生成以及 OpenAI 的最新前沿模型提供极速的硬件底座支持。
2)、 智算调度基石:Azure Cobalt 系列(定制 CPU)

AI 时代的算力集群不仅需要 GPU/加速卡进行矩阵计算,同样极其依赖高效的 CPU 进行数据调度、控制流管理和数据预处理。
Azure Cobalt 100:基于 Arm 架构(Neoverse CSS) 打造的 128 核云原生中央处理器。 相比前代常规硬件,它能为 Microsoft Teams 的媒体处理、SQL 服务器以及各类常规云服务提供最高 50% 的性价比提升。
Azure Cobalt 200:已经大规模部署至 Azure 服务器中,升级为 132 个核心 的定制系统级芯片(SoC)。 主要用于支持安全的多租户计算分享,在承载大模型智能体(Agent)的工作流和高密度通用 AI 调度中发挥核心作用。
3)、 微软 AI 芯片的核心底座特征
软硬高度共生(硅片到服务):微软的目标并非完全取代英伟达或AMD,而是利用自研芯片作为“成本杠杆”和“架构闭环”。 微软可以通过调整其 MAI 模型 的微架构去完美贴合 Maia 芯片的设计,让算法直接“刻”在硅片上,从而榨干每一瓦功耗的性能。
微流控内部散热技术(Microfluidics):随着 AI 芯片功耗急剧上升,微软推出了突破性的微流控冷却技术。 在硅片内部蚀刻出微小通道,让冷却液直接穿过芯片内部进行散热,比传统外部冷板的散热效能高出 3 倍,最大温升降低 65%,使未来三维(3D)堆叠高密度 AI 芯片成为可能。
微软的 AI 芯片目前仅能通过租用 Azure 云端虚拟机 或者是直接使用其背后的 Copilot、OpenAI API 接口 来间接享受其算力。
5. Meta MTIA 300

Meta(元宇宙平台)在 AI 芯片领域的定位与微软高度相似,采取的是“完全自研、100%供内部智算中心、不对外售卖”的极致纵向集成策略。
Meta 的自研芯片统称为 MTIA(Meta Training and Inference Accelerator,Meta 训练和推理加速器)。为了摆脱对英伟达的深度依赖并降低庞大的运营成本,Meta 在底层策略上采取了“自研 MTIA + 外采英伟达/AMD”的双轨制,并以业界罕见的“每 6 个月迭代一代”的超高速率疯狂推进自研芯片的部署。
根据 Meta 官方公布的最新技术路线图,其芯片矩阵主要由以下四代核心智算重器构成:
1)、 核心 AI 芯片阵列:MTIA 300 到 500 系列
Meta 通过使用模块化 Chiplet(芯粒)设计,实现了不更换整机架硬件就能每半年升级一次芯片的创举:
MTIA 300(已大规模量产部署):核心定位:专为 Meta 最赚钱的业务——内容排序与广告推荐(R&R)系统的训练与推理而打造。 技术规格:基于 RISC-V 内核与专用处理单元(PE),配备 216GB HBM 高带宽内存,总带宽达 6.1TB/s,功耗(TDP)为 800 瓦。
MTIA 400(代号 Iris,2026年最新部署):核心定位:Meta 首款旨在与市面上最快商业加速器(如英伟达)直接竞争的通用智算芯片。 技术规格:通过双计算芯粒组合使计算密度翻倍。配备 288GB HBM,带宽飙升至 9.2TB/s。原生支持增强型 MX8 和 MX4 低精度数据格式,MX4 算力达到惊人的 12 PFLOPs,功耗为 1200 瓦。
MTIA 450(预定 2027 年初大规模部署):核心定位:标志着 Meta 自研芯片正式从“推荐算法”全面转向“生成式 AI(GenAI)推理”。 技术规格:HBM 带宽比 400 再次翻倍(达到 18.4 TB/s)以极速加快大模型解码速度。引入了自研的硬件级加速,专门攻克大模型推理中 Softmax 和 FlashAttention 的计算瓶颈。功耗高达 1400 瓦。
MTIA 500(预定 2027 年底前上线):核心定位:极具前瞻性的生成式 AI 超低成本推理旗舰。 技术规格:将模块化推向极致,采用 2×2 的小计算芯粒配置,四周围绕多堆栈 HBM 和双网络芯粒,MX4 算力在 450 的基础上再次提升 43%。
2)、 Meta AI 芯片战略的核心支柱
全面绑定 PyTorch 原生生态(零摩擦迁移):作为 PyTorch 深度学习框架的创始者,Meta 的软件栈拥有无可比拟的先天优势。 MTIA 的软件栈深度集成于 torch.compile 和 torch.export。开发人员不需要对代码进行任何重写,大模型就能在英伟达 GPU 和 Meta 自研 MTIA 之间无缝切换运行。
携手博通(Broadcom)冲刺 2 纳米(2nm)工艺:Meta 已与 博通(Broadcom)签署了长期定制加速器合作协议。双方计划在未来几年内部署多吉瓦(GW)级别的庞大定制 AI 基础设施,且未来的 MTIA 芯片将率先向 2 纳米先进制程 发起冲击。
服务内部,不搞云服务外租:不同于谷歌 TPU 或亚马逊 Trainium 会通过云平台外租赚钱,Meta 所有的 AI 芯片全部用于其内部服务(驱动 Llama 4/5 系列大模型的推理、Instagram/Facebook 的千人千面推荐、智能体 AI 系统的生成等)。
即便自研芯片进度飞快,Meta 首席执行官马克·扎克伯格依然在疯狂采购外部算力。例如,Meta 采购了数十万块英伟达 GPU,并与 AMD 签署了高达 6 吉瓦的 Instinct GPU 采购协议,以此确保其在前沿大模型军备竞赛中绝不掉队。
6. TESLA AI5

特斯拉下一代AI5芯片已成功流片,单颗芯片算力达到前代(AI4)的5倍,主要用于自动驾驶、Robotaxi及人形机器人。特斯拉自研AI芯片分为车载计算平台与云端训练集群两条主线,且正以每9个月迭代一代的速度加速研发,力求实现更高能效与更低成本。
- 车载推理芯片路线
AI5 (最新一代):单芯算力约等于双SoC AI4的5倍,预计于2027年由三星与台积电量产。定位不再局限于自动驾驶,也为人形机器人等具身智能提供算力支持。
HW4 / AI4:目前主力装车芯片,采用7nm工艺,算力约为216 TOPS,支持FSD V12端到端模型推理。
HW3 / FSD 1.0:早期自研芯片,采用三星14nm工艺,算力约144 TOPS,搭载于早期的Model 3/Y等车型。
- 云端训练芯片 (Dojo)
为了训练庞大的视觉和自动驾驶神经网络,特斯拉不仅依赖外部购买的英伟达计算集群,还在自研专属的超级计算机芯片架构:
Dojo架构:采用特斯拉自研的D1芯片拼装成计算模块。
Dojo系统:在算力扩展与功耗优化上具有高度专一性,专门为大规模自动驾驶视频数据的处理与模型训练设计。
- 未来规划
特斯拉已制定激进的研发路线图,AI6、AI7等后续芯片已在早期开发阶段或规划中,目标是将芯片设计周期缩短至9个月,以应对AI模型快速进化的算力需求。
7. AMD MI300

AMD凭借MI300系列GPU在推理端发力,其数据中心GPU年产值已突破50亿美元大关,成为历史上增长最快的硬核产品;后续正加码MI355和MI450系列以扩大市占率。
AMD(超威半导体)在AI芯片领域采取“数据中心算力(GPU/CPU)+ 端侧消费级(AI PC)”的双引擎战略,是目前全球市场上挑战英伟达(NVIDIA)最主要的竞争力量之一。
AMD的AI芯片产品线主要划分为以下两大核心阵列:
1)、 数据中心级 AI 加速卡:Instinct MI 系列
这是AMD对标英伟达H100/B200/Blackwell系列的核心重器,采用专为高性能计算与AI打造的 CDNA 架构:
AMD Instinct MI300X / MI325X(CDNA 3 架构):MI300X 是AMD在AI算力市场的破局之作,配备192GB HBM3内存,已被微软、Meta、OpenAI等科技巨头大规模部署。 MI325X 升级至 256GB HBM3E 内存,提供 6 TB/s 的带宽,在提示词大模型推理性能上表现强劲。
AMD Instinct MI350 系列(MI350X / MI355X,CDNA 4 架构):基于台积电 3nm 工艺,配备 288GB HBM3E 高带宽内存。 原生支持低精度 FP4 和 FP6 数据格式,大幅提升生成式大模型的推理速度,官方宣称其性能和性价比直接对标并超越英伟达部分Blackwell平台。其中,MI355X 更是支持高达 1400W 功耗的液冷扩展配置。
AMD Instinct MI400 / MI450 系列(下一代):采用全新升级的 CDNA “Next” 架构。其最新旗舰 MI450 系列定于 2026 年进入大规模量产,旨在全方位与英伟达展开顶峰对决,满足云服务商对高密度全栈算力集群的极高需求。
2)、 消费端与边缘侧:Ryzen AI(锐龙 AI)处理器
在端侧(AI PC)领域,AMD 是行业普及的领头羊,将 CPU、GPU 与 NPU(神经网络处理单元) 深度集成:
AMD Ryzen AI 400 及 Max+ 系列:专为新一代 AI 笔记本电脑、移动工作站及掌机打造,算力最高可达 60 NPU TOPS,全面支持微软 Copilot+ PC 的本地 AI 体验。 包括 Ryzen AI 9 HX 475 等型号,能够完美地在设备端流畅运行本地大语言模型(LLM)并加速创作者的工作流。
AMD Ryzen AI PRO 400 系列:面向企业级商用台式机与办公本,在提供高能效本地 AI 算力的同时,引入了 AMD PRO 级别的远程安全管理防护。
3)、 核心软硬件生态支撑
ROCm 软件栈(目前已更新至 ROCm 7.2):AMD 正通过全面开源的 AMD ROCm 开放生态 大力追赶英伟达的 CUDA。目前已实现对 PyTorch、TensorFlow 以及大热的 ComfyUI 等主流 AI 框架的“零日(Day-Zero)”原生支持。
EPYC(霄龙)CPU 的协同:在数据中心集群中,AMD 的 EPYC 服务器 CPU 与 Instinct GPU 形成了强有力的双引擎搭配。随着智能体(Agent)等复杂逻辑波次的兴起,CPU 在 AI 调度中的地位正在重新放大。
8. 英特尔的Gaudi 3加速卡

英特尔(Intel)在AI芯片领域采取的是“三线并进”的全栈战略,将算力广泛部署于数据中心、企业级智算和大众消费端。虽然在数据中心顶级GPU市场上英特尔面临巨大挑战,但其通过差异化的架构(ASIC加速卡、至强CPU、酷睿Ultra处理器)构建了独特的AI版图。
英特尔的核心AI芯片产品线主要划分为以下三大阵列:
1)、 数据中心级 AI 加速器:Gaudi 与 数据中心 GPU
针对大模型训练与推理,英特尔采取了“双轨制”硬件路线:
Intel Gaudi 3(专用AI加速卡):定位与架构:采用 5nm 工艺,集成 64 个张量处理器核心(TPC)和 8 个矩阵乘法引擎(MME)。 核心优势:主打极致的性价比,原生集成 24 个 100Gb 标准以太网接口,极大地降低了集群扩展的网络成本。主要针对 Llama、Mistral 等主流大模型的微调(Fine-tuning)和企业级 RAG(检索增强生成)推理负载。
下一代“Crescent Island(新月岛)”系列(数据中心 GPU):由于之前宏大的 Falcon Shores 架构计划调整,英特尔将重心转向了更注重能效比与落地成本的 Crescent Island GPU。 该系列计划采用全新的 Xe3P 微架构,配备高达 160GB 的 LPDDR5X 内存,针对风冷服务器环境进行深度优化,主攻企业级高效 AI 推理。
2)、 智算基石:Xeon(至强)服务器处理器
英特尔始终强调“CPU 也是 AI 芯片”的理念,通过在通用处理器中内置 AI 加速单元来争夺推理市场:
Intel Xeon 6(至强 6 处理器):内置 AMX(高级矩阵扩展) 硬件加速技术,专门用于加速生成式 AI 和通用计算负载。 混合部署优势:在企业级应用中,至强 6 负责处理高并发的小模型推理、数据预处理及向量数据库检索,可与 Gaudi 3 组成高性能、低成本的“CPU+GPU混合算力层”。
Clearwater Forest(至强高能效系列):采用英特尔尖端的 Intel 18A 工艺节点,具备超高密度的核心架构,为云原生 AI 及边缘网络计算提供极致的每瓦性能。
3)、 消费端与客户端:Core Ultra(酷睿 Ultra)AI PC 处理器
在端侧 AI(AI PC)领域,英特尔是生态推进速度最快的厂商之一,通过 CPU+GPU+NPU(神经网络处理单元)的三合一异构算力全面铺开:
Core Ultra 200V / 200H 系列(Lunar Lake / Arrow Lake):已经全面商用,其中 Lunar Lake 平台的整体 AI 算力大幅突破,配备全新第四代 NPU,全面满足微软 Copilot+ PC 的严格端侧算力认证。
Core Ultra 300 系列(Panther Lake,下一代):基于 Intel 18A 工艺打造的旗舰移动处理器,旨在实现端侧大语言模型(LLM)和 Agent(智能体)在笔记本等设备上的超长续航与高速本地响应。
Nova Lake(未来路线图):预计将采用更先进的制程,通过革命性的 Coyote Cove 性能核架构,大幅拉高未来 PC 端侧全场景 AI 的算力上限。
4)、 软件与开放生态:oneAPI 与 OPEA
oneAPI 开放软件栈:为了打破英伟达 CUDA 的软件垄断,英特尔主导了开源的 Intel oneAPI 框架,允许开发者编写一套代码即可在 CPU、GPU、ASIC 等多种硬件上无缝运行。
OPEA(企业AI开放平台):英特尔联合行业伙伴力推 OPEA 行业标准,将基于企业知识库的 AI 应用(如 RAG 智能客服、企业 Agent)转变为标准化的微服务,以此吸引大量企业级用户拥抱英特尔软硬件平台。
英特尔由于产品过渡与软件生态(Synapse)处于阵痛期,其AI加速器年产值未达预期的5亿美元;英特尔目前正依靠Xeon 6服务器CPU的回暖重整旗鼓。
总结
NVIDIA在 raw 性能和CUDA生态领先;
AMD/Intel在性价比,两家正通过开源软件生态全力突围;
ASIC(如TPU/Trainium/Maia)在特定工作负载+云成本上更优(功耗/美元更好)。
1)进展速度:2025-2026迭代加速(Blackwell ➡ Rubin;Gaudi3 ➡ Jaguar;Maia 200等)。重点转向inference(推理需求爆炸)和能效(数据中心功耗瓶颈)。
2)挑战:供应链(TSMC主导先进制程)、软件兼容(NVIDIA CUDA壁垒)、地缘/出口限制。
3)前景: hyperscalers 自研将持续,NVIDIA通过软件+全栈(DGX等)维持领先。AMD/Intel抓住企业/成本市场机会。
以上就是文章全部内容,欢迎补充纠错。若您觉得内容有帮助,建议收藏备用。您的收藏也是对我做内容的最大鼓励和支持,谢谢!
评论
请 登录 或 注册 后参与评论。